How to collect, organize, document, and deploy specialized knowledge for Claude and other AI coding agents
The Skills Revolution
AI coding agents are powerful, but they’re generalists. They’ve been trained on vast amounts of code, but that breadth comes at a cost — they often produce “plausible but wrong” output when working in specialized domains.
Enter Agent Skills: structured knowledge bundles that transform generalist AI into domain specialists. Think of skills as procedural manuals that tell the AI exactly how to work in your context.
💡 Not a Medium member? You can read this article for free using this friend link.
This article provides a practical guide to building your own skills library, covering:
- What makes a good skill
- Sources to collect from
- Organization strategies
- Documentation standards
- Import workflows
- Deployment to Claude Code

Understanding Skills vs. Tools
Before diving in, let’s clarify an important distinction:
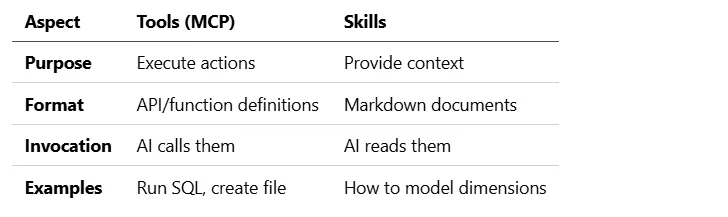
Tools let the AI do things. Skills teach the AI how to do them correctly.
Both are essential. A tool can run dbt commands, but without a skill explaining dbt best practices, the AI might run the wrong commands.
Anatomy of a Great Skill
A well-structured skill has these components:
---
name: building-dimensional-models
description: How to create fact and dimension tables using Kimball methodology
allowed-tools: [Bash, Read, Write, Edit, Glob, Grep]
user-invocable: false
tags: [dimensional-modeling, kimball, star-schema]
metadata:
author: your-team
version: "1.0"
---
# Building Dimensional Models
## When to Use This Skill
[Trigger conditions-when should the AI apply this knowledge?]
## Core Principles
[Fundamental rules that must always be followed]
## Step-by-Step Process
[Procedural guidance with examples]
## Common Mistakes to Avoid
[Anti-patterns and corrections]
## Examples
[Real code samples from your codebase]
Key Attributes

Skills to Collect: A Comprehensive Catalog
1. Data Modeling Skills
Data Vault Modeling
skills/
└── data-vault/
├── SKILL.md # Overview and when to use
├── references/
│ ├── hub-patterns.md # Hub creation patterns
│ ├── link-patterns.md # Link relationship patterns
│ ├── satellite-patterns.md
│ ├── pit-tables.md # Point-in-Time tables
│ └── bridge-tables.md # Business keys spanning links
└── examples/
├── customer-hub.sql
└── order-link.sql
Key skills to document:
- Hub identification from business keys
- Link creation for M:N relationships
- Satellite design for descriptive attributes
- Hash key generation standards
- Loading patterns (insert-only satellites)
Dimensional Modeling (Kimball)
skills/
└── dimensional/
├── SKILL.md
├── references/
│ ├── scd-types.md # SCD1, SCD2, SCD3 patterns
│ ├── fact-types.md # Transaction, snapshot, accumulating
│ ├── dimension-types.md
│ ├── conformed-dimensions.md
│ └── bridge-tables.md
└── examples/
├── customer-scd2.sql
└── sales-fact.sql
Key skills to document:
- When to use SCD1 vs SCD2
- Fact table grain decisions
- Degenerate dimensions
- Role-playing dimensions
- Junk dimensions
Anchor Modeling (6NF)
skills/
└── anchor-modeling/
├── SKILL.md
├── references/
│ ├── anchors.md # Anchor entities
│ ├── attributes.md # Historized attributes
│ ├── ties.md # Relationships
│ └── knots.md # Shared domain values
└── examples/
2. Platform-Specific Skills
Databricks Best Practices
skills/
└── databricks/
├── SKILL.md
├── references/
│ ├── unity-catalog.md # Catalog/schema/table structure
│ ├── delta-lake.md # ACID transactions, time travel
│ ├── photon-optimization.md
│ ├── cluster-sizing.md
│ ├── sql-warehouse.md
│ └── medallion-architecture.md
└── examples/
Key skills to document:
- Unity Catalog naming conventions
- Delta Lake MERGE patterns
- Z-ordering strategy
- Liquid clustering decisions
- Cost optimization techniques
Snowflake Best Practices
skills/
└── snowflake/
├── SKILL.md
├── references/
│ ├── warehouse-sizing.md
│ ├── clustering-keys.md
│ ├── streams-tasks.md
│ ├── dynamic-tables.md
│ └── secure-views.md
BigQuery Best Practices
skills/
└── bigquery/
├── SKILL.md
├── references/
│ ├── partitioning.md
│ ├── clustering.md
│ ├── materialized-views.md
│ └── slot-optimization.md
3. dbt Skills
skills/
└── dbt/
├── using-dbt/
│ └── SKILL.md # General dbt usage
├── dbt-modeling/
│ └── SKILL.md # Model structure
├── dbt-testing/
│ └── SKILL.md # Test patterns
├── dbt-macros/
│ └── SKILL.md # Macro development
└── references/
├── ref-function.md
├── incremental-models.md
├── sources.md
├── exposures.md
└── semantic-layer.md
Import from dbt-agent-skills:
from mdde.skills import SkillImporter
importer = SkillImporter(target_dir="./skills/dbt")
importer.import_dbt_skills() # Clones github.com/dbt-labs/dbt-agent-skills
4. SQL Best Practices
skills/
└── sql/
├── SKILL.md
├── references/
│ ├── window-functions.md
│ ├── cte-patterns.md
│ ├── anti-join-patterns.md
│ ├── aggregation-strategies.md
│ ├── null-handling.md
│ └── performance-hints.md
└── dialect/
├── snowflake-sql.md
├── databricks-sql.md
├── bigquery-sql.md
└── postgres-sql.md
Key skills to document:
- CTEs vs subqueries (when each is better)
- Window function patterns
- Efficient JOINs
- NULL handling best practices
- Platform-specific SQL extensions
5. Visualization & Reporting (IBCS)
skills/
└── ibcs/
├── SKILL.md
├── references/
│ ├── notation-standards.md # SAY, UNIFY, CONDENSE, CHECK
│ ├── chart-types.md # When to use what
│ ├── table-design.md
│ ├── color-usage.md # Semantic colors
│ └── small-multiples.md
└── examples/
├── variance-charts.md
└── waterfall-charts.md
Key skills to document:
- IBCS SUCCESS formula
- Scenario coloring (AC, PY, PL, FC)
- Structure highlighting
- Message hierarchy
- Table layout standards
6. Model-Driven Data Engineering (MDDE)
skills/
└── mdde/
├── SKILL.md
├── references/
│ ├── stereotypes.md # dv_hub, dim_scd2, etc.
│ ├── metadata-first.md # Metadata before code
│ ├── generator-patterns.md # Code generation
│ ├── quadrant-model.md # Q1-Q4 classification
│ └── governance-rules.md
└── examples/
Organizing Your Skills Library
Directory Structure
.claude/
└── skills/ # Claude Code skills location
├── core/ # Always-active skills
│ ├── sql-standards/
│ └── code-style/
├── modeling/ # Invoked when modeling
│ ├── data-vault/
│ ├── dimensional/
│ └── anchor/
├── platforms/ # Platform-specific
│ ├── databricks/
│ ├── snowflake/
│ └── bigquery/
├── tools/ # Tool-specific
│ ├── dbt/
│ └── spark/
└── standards/ # Organizational standards
├── ibcs/
├── naming/
└── testing/
Naming Conventions

Tagging Strategy
Use consistent tags for discovery:
# Methodology tags
tags: [data-vault, dimensional, anchor, mdde]
# Platform tags
tags: [databricks, snowflake, bigquery, synapse]
# Tool tags
tags: [dbt, spark, airflow, dagster]
# Domain tags
tags: [modeling, testing, quality, governance]
# Audience tags
tags: [beginner, intermediate, advanced]
Documenting Skills Effectively
The WHAT-WHEN-HOW-AVOID Structure
Every skill should answer four questions:
# Skill Name
## What Is This?
[Brief explanation of the concept or pattern]
## When to Use
[Specific triggers-what user request or code situation activates this skill]
## How to Apply
[Step-by-step guidance with code examples]
## Common Mistakes to Avoid
[Anti-patterns with corrections]
Writing for AI Comprehension
Skills are read by AI, not just humans. Optimize accordingly:
DO:
- Use explicit, unambiguous language
- Provide concrete examples with actual code
- State rules as imperatives (“Always X”, “Never Y”)
- Include decision trees for complex choices
DON’T:
- Use vague language (“consider”, “might want to”)
- Assume context the AI doesn’t have
- Reference external documents without excerpts
- Leave ambiguity in rule application
Example: Well-Written Skill Section
## Creating a Hub Table
### When to Apply
Use this pattern when:
- You have a business entity with a natural key
- The entity needs to be tracked historically
- Multiple sources provide data about this entity
### Required Columns
Every hub MUST have these columns:
1. \`{entity}_hk\` - Hash key (SHA-256 of business key)
2. \`{entity}_bk\` - Business key (natural key from source)
3. \`load_dts\` - Load timestamp (when record first appeared)
4. \`record_source\` - Source system identifier
### SQL Template
\`\`\`sql
CREATE TABLE {{ schema }}.hub_{{ entity_name }} (
{{ entity_name }}_hk BINARY(32) NOT NULL,
{{ entity_name }}_bk VARCHAR(100) NOT NULL,
load_dts TIMESTAMP_NTZ NOT NULL,
record_source VARCHAR(50) NOT NULL,
CONSTRAINT pk_hub_{{ entity_name }} PRIMARY KEY ({{ entity_name }}_hk)
);
Common Mistakes
❌ Wrong: Including descriptive attributes in the hub
✅ Right: Move descriptive attributes to satellites
❌ Wrong: Using surrogate keys from source systems
✅ Right: Generate hash keys from business keys
Importing External Skills
From GitHub Repositories
---
## Importing External Skills
### From GitHub Repositories
\`\`\`python
from mdde.skills import SkillImporter
# Import dbt official skills
importer = SkillImporter(target_dir=".claude/skills/dbt")
collection = importer.import_from_github(
repo_url="https://github.com/dbt-labs/dbt-agent-skills",
branch="main",
)
print(f"Imported {len(collection.skills)} skills")
for skill in collection.skills:
print(f" - {skill.name}: {skill.metadata.description}")
From Local Directories
# Import company-internal skills
importer = SkillImporter(target_dir=".claude/skills/internal")
collection = importer.import_from_directory(
source_dir="/path/to/company-skills",
)
Converting Formats
# Convert dbt format to Claude format
for skill in collection.skills:
importer.convert_to_claude_format(
skill,
output_dir=".claude/skills/claude-ready"
)
Deploying to Claude Code
Skill File Locations
Claude Code looks for skills in:
- Project-level:
.claude/skills/in your project - User-level:
~/.claude/skills/for personal skills - Organization-level: Via MCP server exposure
Making Skills Discoverable
Add a manifest for skill discovery:
# .claude/skills/manifest.yaml
version: "1.0"
collections:
- name: data-modeling
path: modeling/
description: Data modeling patterns and standards
- name: platform-guides
path: platforms/
description: Platform-specific best practices
- name: dbt
path: tools/dbt/
description: dbt-specific guidance
Testing Your Skills
Before deploying, validate:
from mdde.skills import SkillLoader
loader = SkillLoader()
collection = loader.load_directory(".claude/skills")
# Check all skills parse correctly
for skill in collection.skills:
assert skill.metadata.name, f"Missing name in {skill}"
assert skill.content, f"Empty content in {skill}"
print(f"✓ {skill.name}")
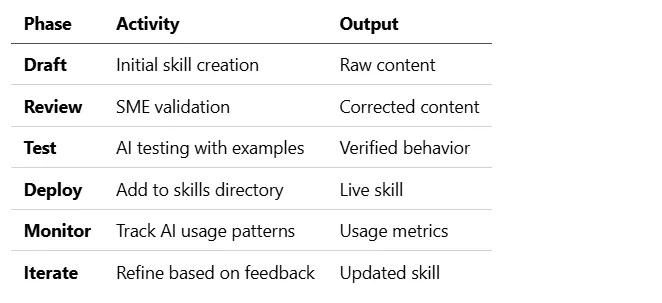
Building a Skills Pipeline
Continuous Improvement Workflow
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Collect │────►│ Organize │────►│ Document │
│ (sources) │ │ (structure)│ │ (content) │
└─────────────┘ └─────────────┘ └─────────────┘
▲ │
│ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Iterate │◄────│ Deploy │◄────│ Review │
│ (feedback) │ │ (Claude) │ │ (validate) │
└─────────────┘ └─────────────┘ └─────────────┘
Source Collection Checklist
External Sources:
- dbt-agent-skills (official dbt skills)
- Platform documentation (Databricks, Snowflake, etc.)
- Industry standards (IBCS, Data Vault, Kimball)
- Open-source project READMEs
Internal Sources:
- Existing documentation
- Code review comments (patterns identified)
- Post-mortem learnings
- Subject matter expert interviews
Skill Lifecycle
Advanced Patterns
Skill Composition
Build complex skills from simpler ones:
---
name: complete-data-vault-implementation
requires:
- data-vault-hubs
- data-vault-links
- data-vault-satellites
---
# Complete Data Vault Implementation
This skill combines hub, link, and satellite patterns into
a complete Data Vault loading workflow.
See individual skills for detailed patterns:
- [Hub Patterns](../data-vault-hubs/SKILL.md)
- [Link Patterns](../data-vault-links/SKILL.md)
- [Satellite Patterns](../data-vault-satellites/SKILL.md)
Context-Aware Skills
Use MDDE quadrant classification:
---
name: governance-aware-modeling
applies-to-quadrants: [Q1]
applies-to-stereotypes: [dv_hub, dv_link, dv_satellite]
---
# Q1 Governance Requirements
Entities in Q1 (Facts) require:
- Full documentation (description, data owner, business term)
- Minimum tests (not_null, unique, referential_integrity)
- Temporal modeling (load_dts, record_source)
- Approval workflow before deployment
Dynamic Skill Selection
Let the AI choose skills based on context:
## Skill Selection Guide
When the user asks about data modeling:
1. Check if they mention "Data Vault" → Use data-vault skills
2. Check if they mention "dimension" or "fact" → Use dimensional skills
3. Check if they mention "hub", "link", "satellite" → Use data-vault skills
4. Check file patterns (hub_*, sat_*) → Use data-vault skills
5. Default → Ask user for preferred methodology
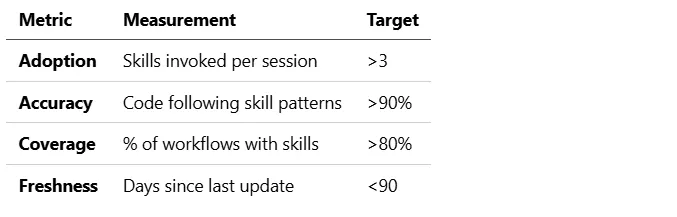
Measuring Success
Skill Effectiveness Metrics
Feedback Collection
# Add to skill footer
---
## Feedback
Was this skill helpful? Issues or improvements?
- Create an issue: [skills-feedback repository]
- Contact: data-platform-[email protected]
Quick Start: Your First Skills Library
Step 1: Create Directory Structure
mkdir -p .claude/skills/{core,modeling,platforms,tools,standards}
Step 2: Import dbt Skills
from mdde.skills import SkillImporter
importer = SkillImporter(target_dir=".claude/skills/tools/dbt")
importer.import_dbt_skills()
Step 3: Create Your First Custom Skill
<!-- .claude/skills/core/sql-standards/SKILL.md -->
---
name: sql-standards
description: SQL coding standards for our organization
allowed-tools: [Read, Write, Edit]
tags: [sql, standards, core]
---
# SQL Coding Standards
## Formatting
- Use UPPERCASE for SQL keywords
- Use lowercase for identifiers
- Indent with 4 spaces
## CTEs
- Always use CTEs over subqueries for readability
- Name CTEs descriptively (not cte1, cte2)
## JOINs
- Always specify JOIN type (INNER, LEFT, etc.)
- Put JOIN conditions on same line for simple joins
- Use separate lines for complex conditions
Step 4: Test with Claude
Ask Claude to write SQL and observe if it follows your standards.
Conclusion
Building a skills library is an investment that compounds over time. Each skill you create:
- Reduces “plausible but wrong” outputs
- Encodes organizational knowledge
- Accelerates onboarding
- Ensures consistency across the team
Start small with core standards, import existing resources like dbt-agent-skills, and iteratively expand based on where the AI struggles or produces inconsistent results.
The future of AI-assisted development isn’t just about better models — it’s about better context. Skills are how you provide that context.
Resources
Repositories
- dbt-agent-skills — Official dbt skills
Standards
- IBCS Standards — Business communication standards
- Data Vault 2.0 — Data Vault methodology
- Kimball Group — Dimensional modeling
